Data for feature store exercise – Vertex AI Feature Store
For this exercise, data is downloaded from Kaggle (link is provided below) and the dataset is listed under CC0 public domain licenses. Data contains information regarding employee promotion data. Since we are not building any model from the data, we are considering only 5 attributes (employee ID, education, gender, no. of trainings, and age), and only 50 samples are considered.
https://www.kaggle.com/datasets/arashnic/hr-ana
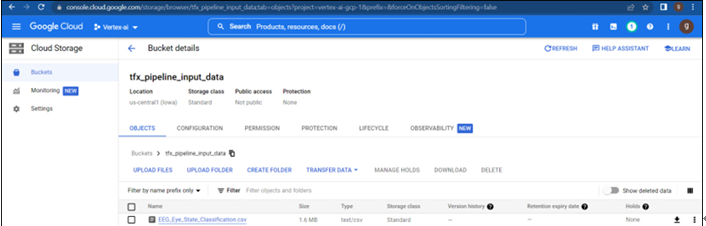
feature_store_input bucket is created under us-centra1 (single region) and the CSV file is uploaded from the bucket as shown in Figure 9.2:
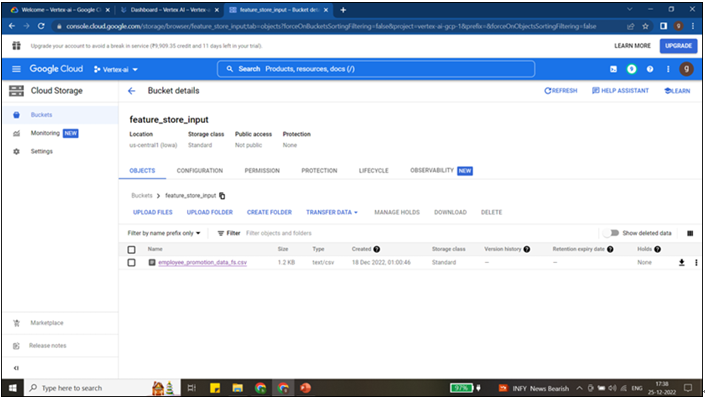
Figure 9.2: Data stored in cloud storage
Working on feature store using GUI
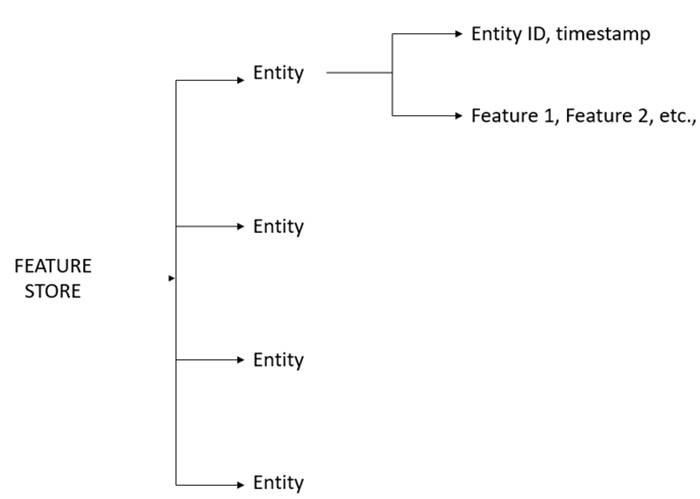
Before we ingest data to the feature store or feature, we need to create a feature store, entity, and features. Resources of the feature store can be created using GUI or Python code. Follow the below-mentioned steps to create the feature store resources using GUI:
Step 1: Opening of feature store.
The landing page of the Vertex AI is shown in Figure 9.3:
Figure 9.3: landing page of Vertex AI
- Click Feature Store to open.
Step 2: Landing page of feature store
Feature stores are region specific; the landing page provides information on the feature store under a specific region as shown in Figure 9.4:
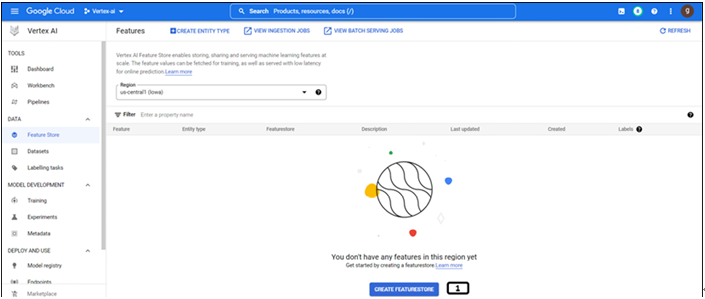
Figure 9.4: Landing page of feature store
- Click CREATE FEATURESTORE.
The region needs to be selected in this step (region cannot be changed post this step).
Step 3: Creation of feature store
Follow the steps mentioned in Figure 9.5 to create a feature store:
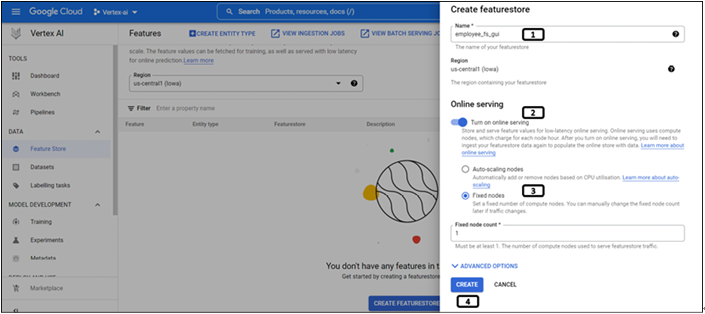
Figure 9.5: Creation of feature store
- Provide a name for the feature store.
- Enable Online Serving if the features need to be made available for low-latency online serving.
- Since the volume of data is small, select Fixed Nodes and provide the value of 1.
- Click on CREATE.
Step 4: Feature store created successfully
Once the feature store is created it will be displayed on the landing page as shown in Figure 9.6:
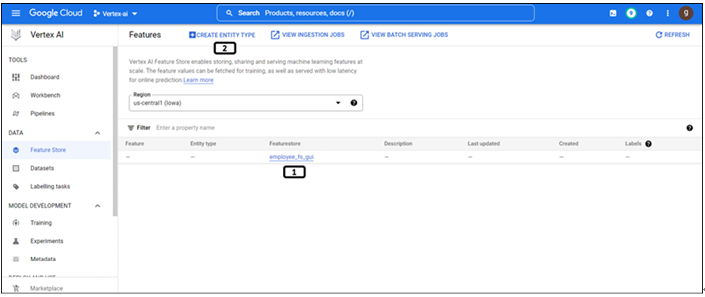
Figure 9.6: Feature store created and listed on the landing page
- Newly created feature store.
- Click on Create Entity Type for its creation.
Step 5: Creation of entity type
Follow the steps shown in Figure 9.7 to create an entity type:
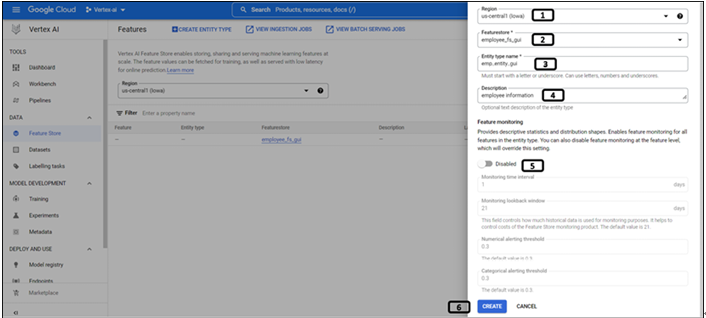
Figure 9.7: Creation of entity type
- Select the Region under which the feature store is created.
- All the feature stores under the region will be listed, select the newly created Featurestore.
- Provide Entity type name.
- Write the Description for the entity type.
- Feature monitoring (enable if the features need to be monitored).
- It enables the monitoring of feature stores and features. Feature store monitors CPU utilization, storage, and latency. Feature monitoring helps in monitoring changes in feature value distribution.
- Click CREATE.