This last chapter of the book covers explainable AI. We will start with understanding what is explainable AI, its need, how explainable AI works on Vertex AI (for image and tabular data) and how to get the explanations from the deployed model.
By the end of this chapter, you will have a good idea about explainable AI and will know how to get the explanations from the deployed model in Vertex AI.
Explainable AI (XAI) is a subfield of Artificial Intelligence (AI) that focuses on developing methods and strategies for using AI in a way that makes the outcomes of the solution understandable to human specialists. The mission of XAI is to ensure that AI systems be open and honest about not just the function they perform but also the purpose they serve. Interpretability is the broader umbrella under AI which includes explainable AI as one of its subcategories. Users can grasp what a model is learning, the additional information it must provide, and the reasoning behind its judgments concerning the problem that exists in the real world that we are seeking to solve, thanks to the model’s interpretability.
Explainable AI is one of the core ideas that define trust in AI systems (along with accountability, reproducibility, lack of machine bias, and resiliency). The aim and ambition shared by data scientists and machine learning technologists is the development of AI that is explainable.
Step 12: Fetching feature values Feature values can be extracted from the feature store with the help of an online service client which has been created in Step 7 (Creation of feature store). Run the following lines of code to fetch data from the feature for a specific employee ID: resp_data = client_data.streaming_read_feature_values( featurestore_online_service.StreamingReadFeatureValuesRequest( entity_type=client_admin.entity_type_path( Project_id, location, featurestore_name, Entity_name ), entity_ids=[“65438”], feature_selector=FeatureSelector(id_matcher=IdMatcher(ids=[“employee_id”,”education”,”gender”,”no_of_trainings”,”age”])), ) ) print(resp_data)
The output will be stored in the resp_data variable and it is an iterator. Run the following lines of code to extract and parse the data from the iterator: names_col=[] for resp in resp_data: if resp.header.feature_descriptors != “”: for head in resp.header.feature_descriptors: names_col.append(head.id) try: values=[] for items in resp.entity_view.data: if items.value.string_value !=””:values.append(items.value.string_value) elif items.value.int64_value !=””:values.append(items.value.int64_value) except:pass print(“Feature Names”,names_col) print(“Feature Values”,values)
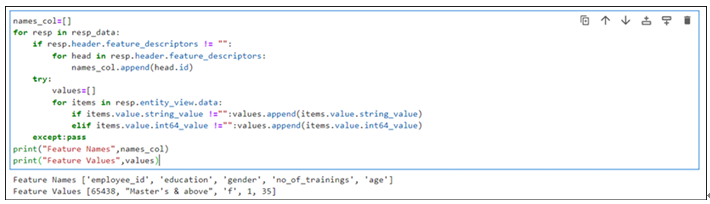
The output of the cell is shown in Figure 9.21:
Figure 9.21: Data extracted from the feature store Deleting resources We have utilized cloud storage to store the data and delete the CSV file from the cloud storage manually. Feature store is a cost-incurring resource on GCP, ensure to delete them. Also, the feature store cannot be deleted from the web console or GUI, we need to delete it through programming. Run the below-mentioned lines of code to delete the feature store (both the feature stores were created using GUI and Python). Check if the landing page of the feature store after running the code to ensure it is deleted (the landing page should look like the Figure 9.4): client_admin.delete_featurestore( request=fs_s.DeleteFeaturestoreRequest( name=client_admin.featurestore_path(Project_id, location, featurestore_name), force=True, ) ).result() featurestore_name=employee_fs_gui client_admin.delete_featurestore( request=fs_s.DeleteFeaturestoreRequest( name=client_admin.featurestore_path(Project_id, location, featurestore_name), force=True, ) ).result()
Below listed are few of the best practices for using Feature store of Vertex AI:
Model features to multiple entities: Some features might be used in multiple entities (like clicks per product at user level). In this kind of scenarios, it is best to create a separate entity to group shared features.
Access control for multiple teams: Multiple teams like data scientists, ML researchers, Devops, and so on, may require access to the same feature store but with different level of permissions. Resource level IAM policies can be used to restrict the access to feature store or particular entity type.
Ingesting historical data (backfilling): It is recommended to stop online serving while ingesting the historical data to prevent any changes to the online store.
Cost optimization:
Autoscaling: Instead of maintaining a high node count, autoscaling allows Vertex AI Feature Store to analyze traffic patterns and automatically modify the number of nodes up or down based on CPU consumption and also works better for cost optimization.
Recommended to provide a startTime in the batchReadFeatureValues or exportFeatureValues request to optimize offline storage costs during batch serving and batch export.
In this chapter, we learned about the feature store of Vertex AI, and worked on the creation of the feature store, entity type, adding features, and ingesting feature values using web console and Python.
In the next chapter, we will start understanding explainable AI, and how explainable AI works on Vertex AI.
Step 8: Creation of entity type Entity type will be created under the newly created feature store using the create_entity_type method. Run the below-mentioned code in a new cell to create the entity type. The output of the last line in the code provides the path of the entity type created. Check the feature store landing page, the newly created feature store, and the entity type will be displayed: entity_creation = client_admin.create_entity_type( fs_s.CreateEntityTypeRequest( parent=client_admin.featurestore_path(Project_id, location, featurestore_name), entity_type_id=Entity_name, entity_type=entity_type.EntityType( description=”employee entity”, ), ) ) print(entity_creation.result())
Step 9: Creation of feature Once the feature store and entity type are created, the feature needs to be created before ingesting the feature values. For each of the features, information on feature ID, type, and description is provided. Run the following-mentioned code in a new cell to add features: client_admin.batch_create_features( parent=client_admin.entity_type_path(Project_id, location, featurestore_name, Entity_name), requests=[ fs_s.CreateFeatureRequest( feature=feature.Feature( value_type=feature.Feature.ValueType.INT64, description=”employee id”, ), feature_id=”employee_id”, ), fs_s.CreateFeatureRequest( feature=feature.Feature( value_type=feature.Feature.ValueType.STRING, description=”education”, ), feature_id=”education”, ), fs_s.CreateFeatureRequest( feature=feature.Feature( value_type=feature.Feature.ValueType.STRING, description=”gender”, ), feature_id=”gender”, ), fs_s.CreateFeatureRequest( feature=feature.Feature( value_type=feature.Feature.ValueType.INT64, description=”no_of_trainings”, ), feature_id=”no_of_trainings”, ), fs_s.CreateFeatureRequest( feature=feature.Feature( value_type=feature.Feature.ValueType.INT64, description=”age”, ), feature_id=”age”, ), ], ).result()
Once the features are created, they are displayed in the output of the cell as shown in Figure 9.19:
Figure 9.19: Addition of features to the feature store using Python
Step 10: Define the ingestion job As seen in the web console, feature values can be ingested from cloud storage or BigQuery. We shall use the same CSV file which has been uploaded to the cloud storage. Importantly, we should also supply the timestamp information while ingesting the values. Timestamps can be provided in the code or there can be a separate column in the data that contains timestamp information. Timestamp information must be in google.protobuf.Timestamp format. Run the following code in a new cell to define the ingestion job: seconds = int(datetime.datetime.now().timestamp()) timestamp_input = Timestamp(seconds=seconds) ingest_data_csv = fs_s.ImportFeatureValuesRequest( entity_type=client_admin.entity_type_path( Project_id, location, featurestore_name, Entity_name ), csv_source=io.CsvSource( gcs_source=io.GcsSource( uris=[ “gs://feature_store_input/employee_promotion_data_fs.csv” ] ) ), entity_id_field=”employee_id”, feature_specs=[ ImportFeatureValuesRequest.FeatureSpec(id=”employee_id”), ImportFeatureValuesRequest.FeatureSpec(id=”education”), ImportFeatureValuesRequest.FeatureSpec(id=”gender”), ImportFeatureValuesRequest.FeatureSpec(id=”no_of_trainings”), ImportFeatureValuesRequest.FeatureSpec(id=”age”), ], feature_time=timestamp_input, worker_count=1, )
Note: If all feature values were generated at the same time, there is no need to have a timestamp column. Users can specify the timestamp as part of the ingestion request. Step 11: Initiation of ingestion job The ingestion job needs to be initiated after it is defined, run the following line of codes to begin the ingestion process: ingest_data = client_admin.import_feature_values(ingest_data_csv) ingest_data.result()
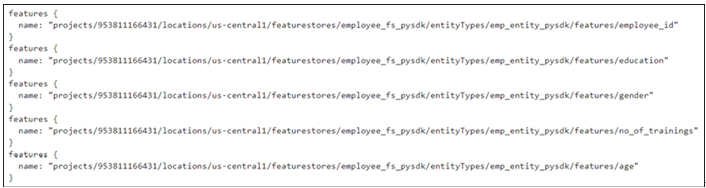
Once the ingestion is complete, it will provide information on the number of feature values ingested as shown in Figure 9.20:
Figure 9.20: Ingestion of feature values using Python
In the previous section, we worked on a feature store for the creation and uploading of feature values using the GUI approach. In this section, we shall create another feature store, ingest values, and also fetch the values from the feature store.
We will be using the Python 3 notebook file to type commands for working on the feature store. Follow the following-mentioned steps to create a Python file and type the Python codes given in this section.
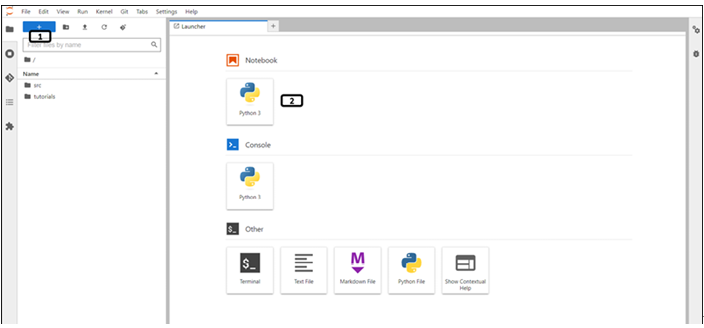
Step 1: Create a Python notebook file Once the workbench is created, open Jupyterlab and follow the steps mentioned in Figure 9.17 to create a Python notebook file:
Figure 9.17: New launcher window of notebook
Click the new launcher.
Double-click the Python 3 notebook file to create one.
Step 2: Package installation Run the following commands to install the google cloud AI platform package. (It will take a few minutes to install the packages): USER=”–user” !pip install {USER} google-cloud-aiplatform
Step 3: Kernel restart Type the following commands in the next cell, to restart the kernel. (users can restart the kernel from the GUI as well): import os import IPython if not os.getenv(“”): IPython.Application.instance().kernel.do_shutdown(True)
Step 4: Importing the installed packages Run the following-mentioned codes in a new cell to import the required packages: import google.cloud.aiplatform_v1 from google.cloud.aiplatform_v1.types import featurestore_service as fs_s from google.cloud.aiplatform_v1.types import featurestore as fs from google.cloud.aiplatform_v1.types import feature from google.cloud.aiplatform_v1.types import entity_type from google.cloud.aiplatform_v1.types import io from google.protobuf.timestamp_pb2 import Timestamp from google.cloud.aiplatform_v1.types.featurestore_service import ImportFeatureValuesRequest from google.cloud.aiplatform_v1.types import FeatureSelector, IdMatcher from google.cloud.aiplatform_v1.types import featurestore_online_service import datetime
Step 5: Setting up the project and other variables Run the following-mentioned line of codes in a new cell to set the project to the current one and also define variables to store the path for multiple purposes: Project_id=”vertex-ai-gcp-1” featurestore_name=”employee_fs_pysdk” Entity_name=”emp_entity_pysdk” location = “us-central1” endpoint = “us-central1-aiplatform.googleapis.com”
Step 6: Connecting to the feature store Connection to the feature store is the first step to work on the feature store. We create a connection to the feature store through the service client to create and ingest values to it using FeaturestoreServiceClient.
FeaturestoreOnlineServingServiceClient is used to fetch the feature values from the feature store. Run the below-mentioned line of codes to complete the connection: client_admin = google.cloud.aiplatform_v1.FeaturestoreServiceClient(client_options={“api_endpoint”: endpoint}) client_data = google.cloud.aiplatform_v1.FeaturestoreOnlineServingServiceClient(client_options={“api_endpoint”: endpoint}) fs_resource_path = client_admin.common_location_path(Project_id, location)
Step 7: Creation of feature store Instead of using the feature store that has been created from the GUI approach, we will create a new one. Feature store name, location, and project information are already in Step 5 (Setting up the project and other variables). Run the following code to create the feature store. The status of the feature store will be displayed in the results, as shown in Figure 9.18. The feature store creation procedure is a long-running operation, they are asynchronous jobs. except PI calls like updating or removing feature stores follow the same procedure. create_fs = client_admin.create_featurestore( fs_s.CreateFeaturestoreRequest( parent=fs_resource_path, featurestore_id=featurestore_name, featurestore=fs.Featurestore( online_serving_config=fs.Featurestore.OnlineServingConfig( fixed_node_count=1 print(create_fs.result()) client_admin.get_featurestore(name=client_admin.featurestore_path(Project_id, location, featurestore_name))
The entity type is created successfully as shown in Figure 9.8 under the selected feature store:
Figure 9.8: Entity type created and listed on the landing page
Click the newly created Entity type.
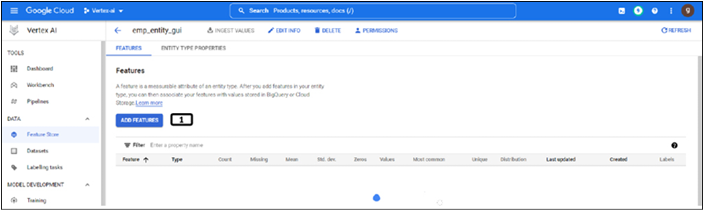
Step 7: Creation of features
Once the entity type is created, features need to be created before ingesting the values. Follow the steps mentioned in Figure 9.9 to create features:
Figure 9.9: Creation of features
Click ADD FEATURES.
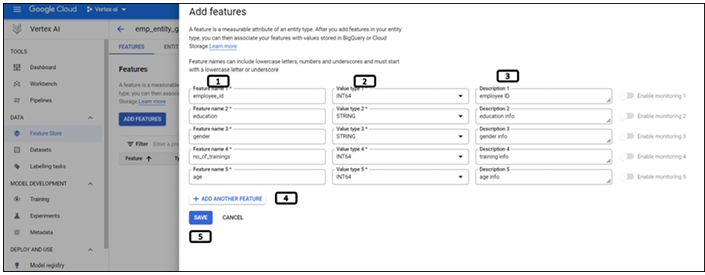
A new side tab will pop out to enter the features as shown in Figure 9.10, follow the below steps to create the features:
Figure 9.10: Adding user input for feature creation
Enter the Feature name.
Enter the Value type stored in that feature.
Enter the Description for the feature.
Click Add Another Feature to add new features.
Click SAVE, once all the features are added.
Step 8: Features created successfully
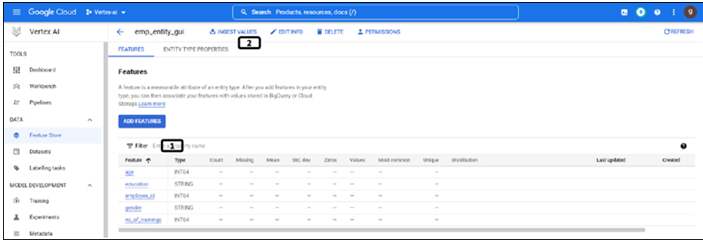
Once the features are created successfully, they are displayed on the entity type page as shown in Figure 9.11:
Figure 9.11: Features listed under the entity type
Newly created features are displayed in tabular format.
Click on Ingest Values to add the feature values.
Step 9: Ingesting feature values
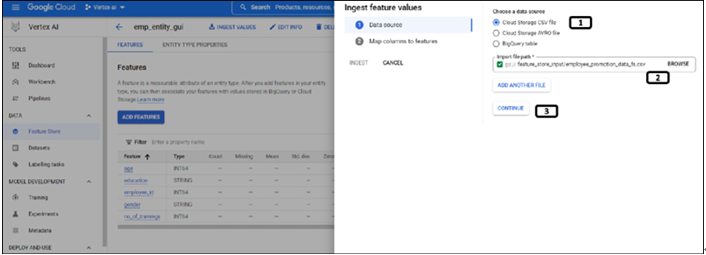
Follow the steps mentioned in Figure 9.12 to initiate the ingestion of feature values:
Figure 9.12: Importing data to features
Data can be ingested from cloud storage or BigQuery. Select Cloud Storage CSV file.
Select the CSV file from the cloud storage by clicking BROWSE.
Click CONTINUE and follow the steps mentioned in Figure 9.13:
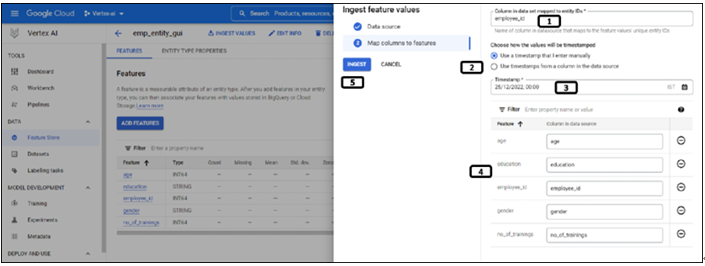
After selecting the data source, we need to map the columns of the data source to the features. Follow the steps mentioned in the Figure 9.13 to map the features:
Figure 9.13: Mapping of columns to features
Add employee ID, since that is the column which is containing unique values.
Select to enter the Timestamp manually. If data contains the timestamp values, the same column can be used here.
Select the date and time.
Map the column names in the CSV file to the features.
Click INGEST to initiate the ingestion job.
Step 10: Ingestion job successful
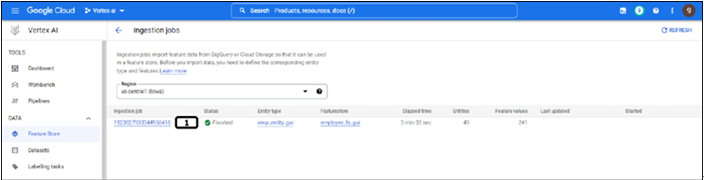
Once the feature values are ingested successfully, the ingestion job status will be updated as shown in Figure 9.14:
Figure 9.14: Ingestion jobs of feature store
The ingestion job is completed successfully.
Step 11: Landing page of feature store after the creation of feature store, entity type, and features
The landing page of the feature store is shown in Figure 9.15, all the features under entity type and feature store are listed and displayed in the tabular format:
Figure 9.15: Landing page of feature store after the creation of features
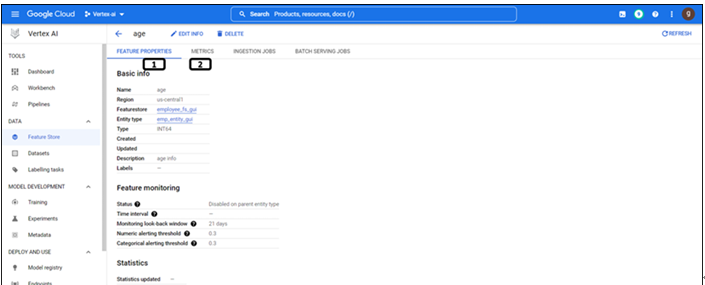
Click the age feature. The window will navigate to the properties of the feature as shown in Figure 9.16:
Figure 9.16: Properties of feature
For all the features, Feature Properties consisting of basic information and statistics are displayed.
Metrics are populated if the monitoring feature is enabled for the feature store and for that particular feature.
For this exercise, data is downloaded from Kaggle (link is provided below) and the dataset is listed under CC0 public domain licenses. Data contains information regarding employee promotion data. Since we are not building any model from the data, we are considering only 5 attributes (employee ID, education, gender, no. of trainings, and age), and only 50 samples are considered.
Before we ingest data to the feature store or feature, we need to create a feature store, entity, and features. Resources of the feature store can be created using GUI or Python code. Follow the below-mentioned steps to create the feature store resources using GUI:
Step 1: Opening of feature store.
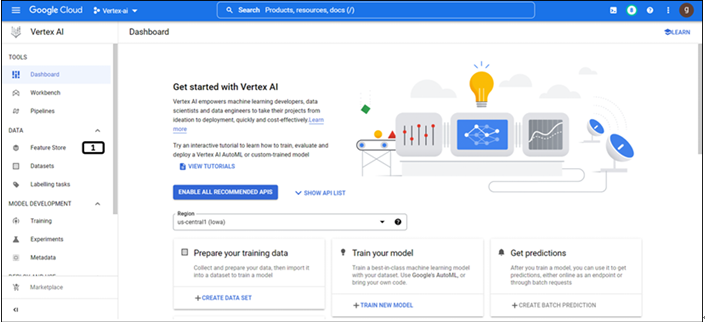
The landing page of the Vertex AI is shown in Figure 9.3:
Figure 9.3: landing page of Vertex AI
Click Feature Store to open.
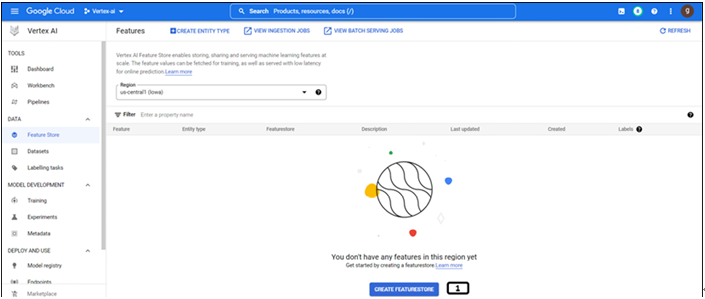
Step 2: Landing page of feature store
Feature stores are region specific; the landing page provides information on the feature store under a specific region as shown in Figure 9.4:
Figure 9.4: Landing page of feature store
Click CREATE FEATURESTORE.
The region needs to be selected in this step (region cannot be changed post this step).
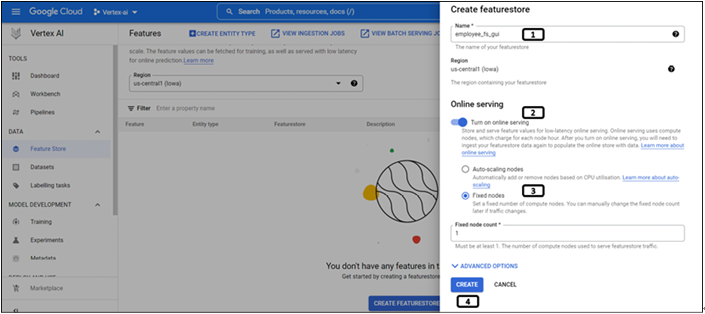
Step 3: Creation of feature store
Follow the steps mentioned in Figure 9.5 to create a feature store:
Figure 9.5: Creation of feature store
Provide a name for the feature store.
Enable Online Serving if the features need to be made available for low-latency online serving.
Since the volume of data is small, select Fixed Nodes and provide the value of 1.
Click on CREATE.
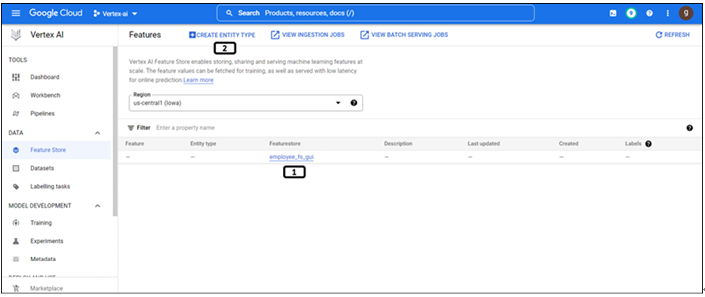
Step 4: Feature store created successfully
Once the feature store is created it will be displayed on the landing page as shown in Figure 9.6:
Figure 9.6: Feature store created and listed on the landing page
Newly created feature store.
Click on Create Entity Type for its creation.
Step 5: Creation of entity type
Follow the steps shown in Figure 9.7 to create an entity type:
Figure 9.7: Creation of entity type
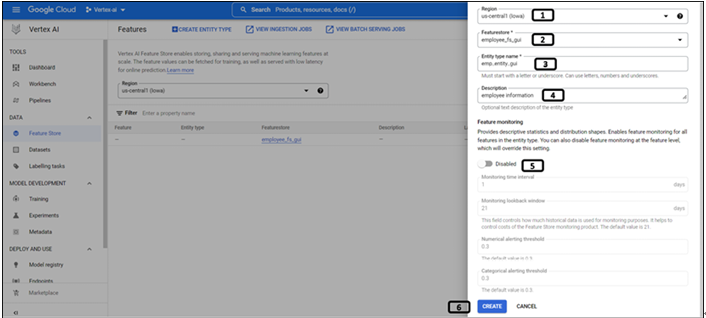
Select the Region under which the feature store is created.
All the feature stores under the region will be listed, select the newly created Featurestore.
Provide Entity type name.
Write the Description for the entity type.
Feature monitoring (enable if the features need to be monitored).
It enables the monitoring of feature stores and features. Feature store monitors CPU utilization, storage, and latency. Feature monitoring helps in monitoring changes in feature value distribution.
Extend features company-wide: Feature stores let you easily share features for training or serving. Different projects and use cases do not need feature re-engineering. Manage and deliver features from a central repository to preserve consistency throughout your business and prevent redundant efforts, especially for high-value features.
Vertex AI Feature Store lets people find and reuse features using search and filtering. View feature metadata to assess quality and usage. For instance, you may check feature coverage and feature value distribution.
Serving at scale: Online forecasts require low-latency feature serving, which Vertex AI Feature Store manages. Vertex AI Feature Store automatically builds and expands low-latency data serving infrastructure. You create features but outsource providing them. Data scientists may create new features without worrying about deployment using this management.
Reduce training-serving bias: Training-serving skew happens when your production feature data distribution differs from the one used to train your model. This skew causes disparities between a model’s training and production performance. Vertex AI Feature Store can handle training-serving bias with these examples:
Vertex AI Feature Store guarantees that feature values are ingested once and reused for training and serving. Without a feature store, training and serving features may use distinct code paths. Training and serving feature values may differ.
Vertex AI Feature Store offers previous data lookups for training. By collecting pre-prediction feature values, these lookups reduce data leakage.
Identify drift: Vertex AI Feature Store detects drift in feature data distribution. Vertex AI Feature Store monitors feature value dispersion. Retrain models using impacted features as feature drift rises.
Retention: The Vertex AI Feature Store preserves feature values for the allotted amount of time. This cap is determined by the feature values’ timestamp, not the date and time the values were imported. Values with timestamps that go beyond the limit are scheduled for deletion by Vertex AI Feature Store.
A feature store has overhead, which can make data science more complicated, especially for smaller projects. A feature store may complicate matters if a business has numerous little data sets. Feature stores are ineffective when the data is so diverse that no standard modeling approach will assist. Reusing features created on separate data sources and metadata is tough. Additionally, a feature store might not be the ideal choice when the features are not time-dependent or when features are needed only for batch predictions.
After learning about the pipelines of the platform, we will move to the feature store of GCP. In this chapter, we will start with an understanding of the feature store, and the advantages of features followed by a hands-on feature store.
By the end of this chapter, users will have a good idea about the feature store, when to use it, and how to employ it with the web console of GCP and Python.
Vertex AI Feature Store is a centralized repository for managing and delivering machine learning features. To speed up the process of creating and delivering high-quality ML applications, many organizations are turning to centralized feature stores to facilitate the sharing, discovery, and re-use of ML features at scale.
The storage and processing power, as well as other components of the backend infrastructure, are handled by Vertex AI Feature Store, making it a fully managed solution. As a result of this strategy, data scientists may ignore the difficulties associated with delivering features into production and instead concentrate on the feature computation logic.
The feature store in Vertex AI is an integral aspect of the overall system. Use Vertex AI Feature Store on its own or include it in your existing Vertex AI workflows. For instance, the Vertex AI Feature Store may be queried for information to be used in the training of custom or AutoML models.
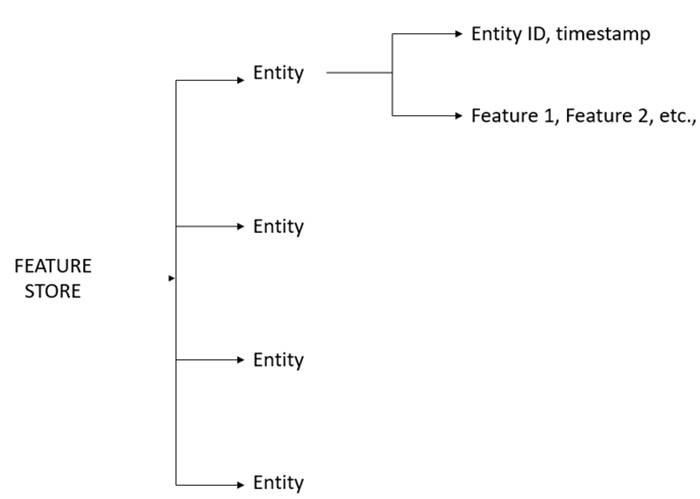
The collection of entities for a certain entity time is stored in a feature store. Fields like entity ID, timestamp, and a series of attributes like feature 1, feature 2, and so on, are all defined for each entity type. The hierarchy of the feature store is described in Figure 9.1:
Figure 9.1: Hierarchy of feature store
Feature store: A top-level container for entity types, features, and their values.
Entity type: A collection of semantically related features (real or virtual).
Entity: An instance of the entity type.
Feature: A measurable property or attribute of an entity type.
Feature values: These contain values of the features at a specific point in time.
We have utilized workbench, cloud storage to store the data and the artifacts of the pipeline. For deletion of resources, ensure to delete the workbench, clear the data stored in the cloud storage.
We learnt about the TFX, a few of its components and constructed pipeline using some of the standard components. Also, we understood how to use Kubeflow for the orchestration of TFX pipeline on vertex AI.
In the next chapter, we will start understanding and working on feature store of the Vertex AI.
Which artifacts of the transform component is used in the training component of the pipeline?
What are the different orchestration options TFX supports?
Try using evaluator component between trainer and pusher component and re-construct the pipeline. (Use evaluator component to evaluate the model performance and push it only if the performance is good).
Step 6: Creation of pipeline Till now we have understood and executed certain components of the tfx pipeline (not all the components are needed for the pipeline construction). Let’s start constructing pipeline using example_gen, statistics_gen, schema_gen, transform, trainer and pusher components (Pusher component is used to push the trained model to a location, in this example trained model we will be pushed to the cloud storage): • Define a function (_create_pipeline) to consisting of all the steps/components that needs to be included in the pipeline and returns the tfx pipeline. Run the below mentioned code in a new cell to define the pipeline function: def _create_pipeline(pl_name, pipeline_root_folder, data_root, module_file_transform, module_file_train, model_dir_save, ) -> tfx.dsl.Pipeline: example_gen_csv = tfx.components.CsvExampleGen(input_base=data_root) gen_statistics = tfx.components.StatisticsGen(examples=example_gen_csv.outputs[‘examples’]) gen_schema = tfx.components.SchemaGen(statistics=gen_statistics.outputs[‘statistics’]) transform_data = tfx.components.Transform(examples=example_gen_csv.outputs[‘examples’],schema=gen_schema.outputs[‘schema’],module_file=os.path.join(MODULE_FOLDER, TRANSFORM_MODULE_PATH)) model_trainer = tfx.components.Trainer( module_file=module_file_train, examples=example_gen_csv.outputs[‘examples’], transform_graph=transform_data.outputs[‘transform_graph’], schema=gen_schema.outputs[‘schema’], train_args=tfx.proto.TrainArgs(num_steps=200), eval_args=tfx.proto.EvalArgs(num_steps=10)) pusher = tfx.components.Pusher( model=model_trainer.outputs[‘model’], push_destination=tfx.proto.PushDestination( filesystem=tfx.proto.PushDestination.Filesystem( base_directory=model_dir_save))) return tfx.dsl.Pipeline( pipeline_name=pl_name, pipeline_root=pipeline_root_folder, components=[example_gen_csv,gen_statistics,gen_schema,transform_data,model_trainer,pusher])
Step 8: Defining a runner As mentioned in the theory section, TFX is portable across environments and orchestration frameworks. TFX supports Airflow, Beam, and Kubeflow. It also provides flexibility for the developers to add their own orchestrators. Orchestrators must inherit TfxRunner. TFX orchestrators schedule pipeline components based on DAG dependencies using the logical pipeline object, which comprises pipeline args, components, and DAG. In our example we will be using Vertex Pipelines together with the Kubeflow V2 dag runner. In the code, we create runner using Kubeflow V2 dag and run it by passing all the pipeline parameters. Run the following mentioned codes to define the runner: trainer_file=”trainer.py” file_transform=os.path.join(MODULE_FOLDER, TRANSFORM_MODULE_PATH) file_train=os.path.join(MODULE_FOLDER, trainer_file) pl_def_file = NAME_PIPELINE + ‘.json’ pl_runner = tfx.orchestration.experimental.KubeflowV2DagRunner( config=tfx.orchestration.experimental.KubeflowV2DagRunnerConfig(), output_filename=pl_def_file) _ = pl_runner.run( _create_pipeline( pl_name=NAME_PIPELINE, pipeline_root_folder=ROOT_PIPELINE, data_root=INPUT_DATA_DIR, module_file_transform=file_transform, module_file_train=file_train, model_dir_save=OUTPUT_MODEL_DIR))
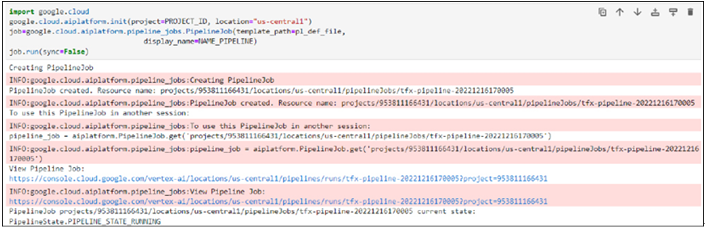
Step 9: Pipeline execution As the last step we need to execute the pipeline. Run the following mentioned codes in a new cell to start the pipeline execution: import google.cloud google.cloud.aiplatform.init(project=PROJECT_ID, location=”us-central1”) job=google.cloud.aiplatform.pipeline_jobs.PipelineJob(template_path=pl_def_file, display_name=NAME_PIPELINE) job.run(sync=False)
Once the pipeline starts, users will be provided the link to check the status as shown in Figure 8.13:
Figure 8.13: Pipeline link
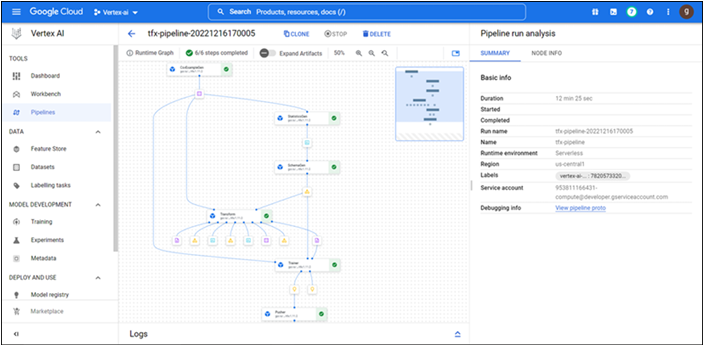
Click on the link to check the status of the pipeline as shown in the following screenshot:
Figure 8.14: Pipeline executed successfully Pipeline will take a few mins to complete the training and push the trained model to the cloud storage. If the pipeline is constructed using tfx or Kubeflow, the user interface of the pipeline in GCP will remain same as shown in Figure 8.14. Spend some time to understand each of the components and its artifacts in detail as described in the previous chapter.