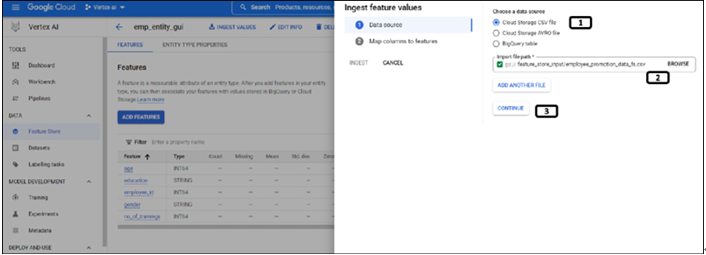
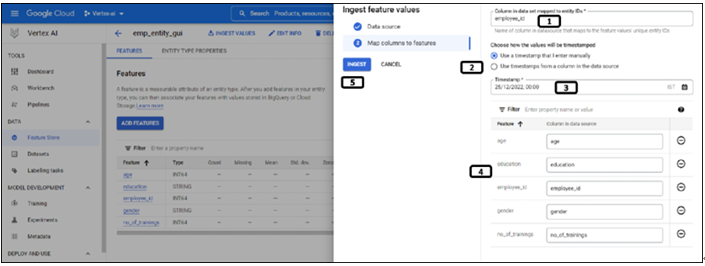
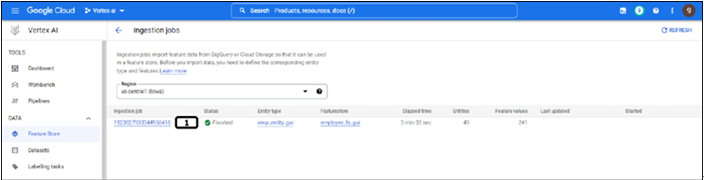
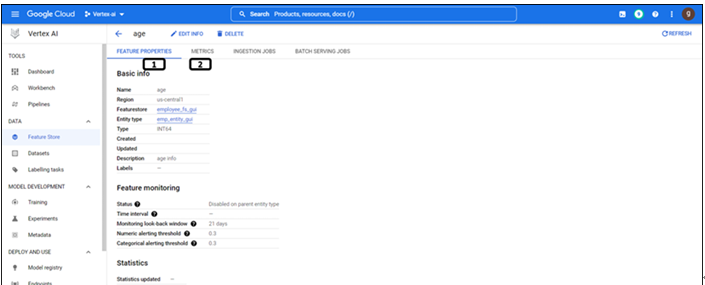
Working on feature store using Python – Vertex AI Feature Store
In the previous section, we worked on a feature store for the creation and uploading of feature values using the GUI approach. In this section, we shall create another feature store, ingest values, and also fetch the values from the feature store.
We will be using the Python 3 notebook file to type commands for working on the feature store. Follow the following-mentioned steps to create a Python file and type the Python codes given in this section.
Step 1: Create a Python notebook file
Once the workbench is created, open Jupyterlab and follow the steps mentioned in Figure 9.17 to create a Python notebook file:
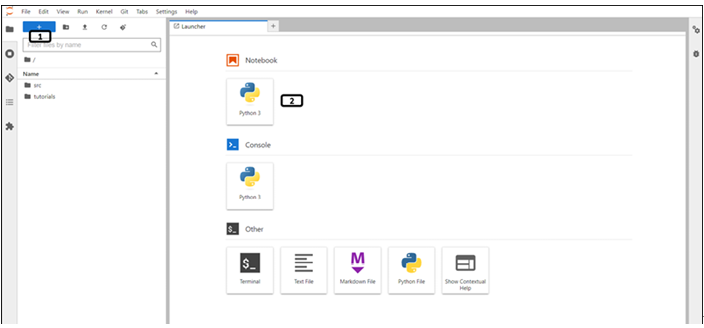
Figure 9.17: New launcher window of notebook
- Click the new launcher.
- Double-click the Python 3 notebook file to create one.
Step 2: Package installation
Run the following commands to install the google cloud AI platform package. (It will take a few minutes to install the packages):
USER=”–user”
!pip install {USER} google-cloud-aiplatform
Step 3: Kernel restart
Type the following commands in the next cell, to restart the kernel. (users can restart the kernel from the GUI as well):
import os
import IPython
if not os.getenv(“”):
IPython.Application.instance().kernel.do_shutdown(True)
Step 4: Importing the installed packages
Run the following-mentioned codes in a new cell to import the required packages:
import google.cloud.aiplatform_v1
from google.cloud.aiplatform_v1.types import featurestore_service as fs_s
from google.cloud.aiplatform_v1.types import featurestore as fs
from google.cloud.aiplatform_v1.types import feature
from google.cloud.aiplatform_v1.types import entity_type
from google.cloud.aiplatform_v1.types import io
from google.protobuf.timestamp_pb2 import Timestamp
from google.cloud.aiplatform_v1.types.featurestore_service import ImportFeatureValuesRequest
from google.cloud.aiplatform_v1.types import FeatureSelector, IdMatcher
from google.cloud.aiplatform_v1.types import featurestore_online_service
import datetime
Step 5: Setting up the project and other variables
Run the following-mentioned line of codes in a new cell to set the project to the current one and also define variables to store the path for multiple purposes:
Project_id=”vertex-ai-gcp-1”
featurestore_name=”employee_fs_pysdk”
Entity_name=”emp_entity_pysdk”
location = “us-central1”
endpoint = “us-central1-aiplatform.googleapis.com”
Step 6: Connecting to the feature store
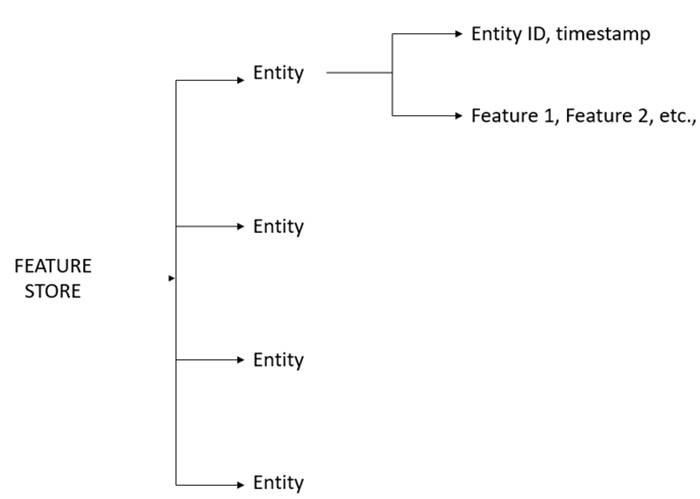
Connection to the feature store is the first step to work on the feature store. We create a connection to the feature store through the service client to create and ingest values to it using FeaturestoreServiceClient.
FeaturestoreOnlineServingServiceClient is used to fetch the feature values from the feature store. Run the below-mentioned line of codes to complete the connection:
client_admin = google.cloud.aiplatform_v1.FeaturestoreServiceClient(client_options={“api_endpoint”: endpoint})
client_data = google.cloud.aiplatform_v1.FeaturestoreOnlineServingServiceClient(client_options={“api_endpoint”: endpoint})
fs_resource_path = client_admin.common_location_path(Project_id, location)
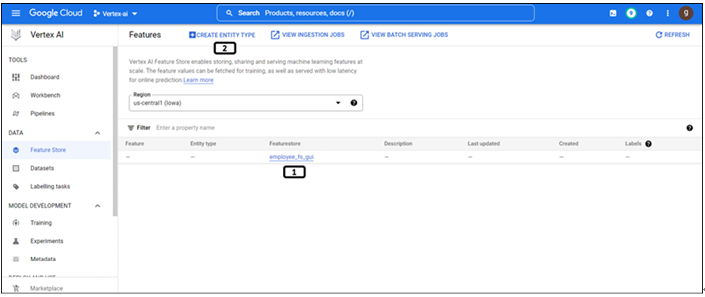
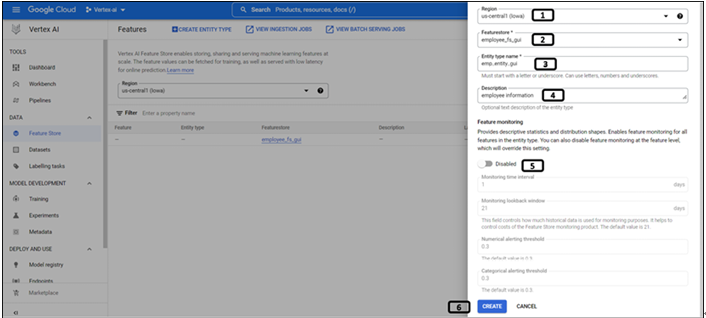
Step 7: Creation of feature store
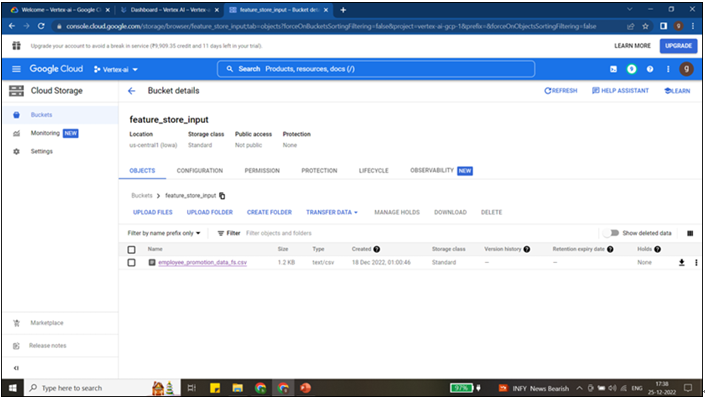
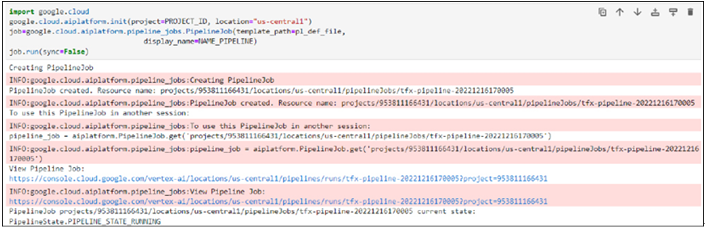
Instead of using the feature store that has been created from the GUI approach, we will create a new one. Feature store name, location, and project information are already in Step 5 (Setting up the project and other variables). Run the following code to create the feature store. The status of the feature store will be displayed in the results, as shown in Figure 9.18. The feature store creation procedure is a long-running operation, they are asynchronous jobs. except PI calls like updating or removing feature stores follow the same procedure.
create_fs = client_admin.create_featurestore(
fs_s.CreateFeaturestoreRequest(
parent=fs_resource_path,
featurestore_id=featurestore_name,
featurestore=fs.Featurestore(
online_serving_config=fs.Featurestore.OnlineServingConfig(
fixed_node_count=1
print(create_fs.result())
client_admin.get_featurestore(name=client_admin.featurestore_path(Project_id, location, featurestore_name))